 |
 |
 |
 |
| Pre-translate with DGT-OmegaT |
| 02 | IA-CS Replace by glossary items | |
|---|---|---|
|
|
|
|
| Pre-translate with DGT-OmegaT |
| 02 | IA-CS Replace by glossary items | |
|---|---|---|
|
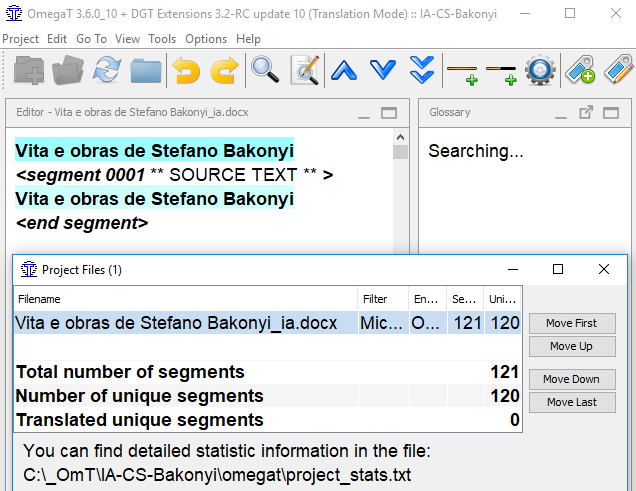
Project IA-CS
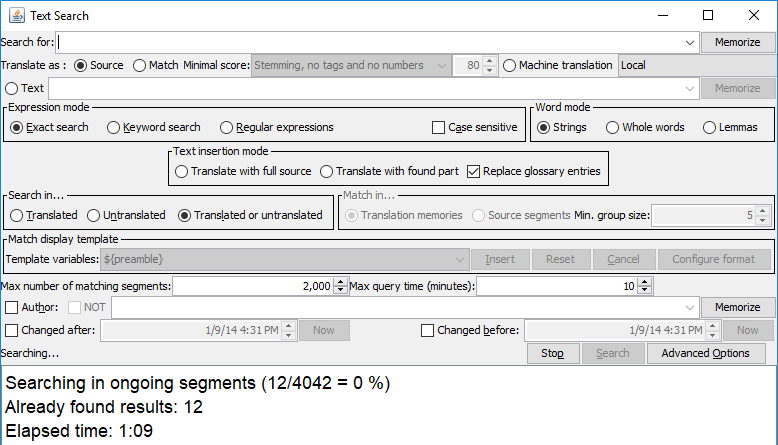
Document: 120 segments Glossary: 91 000 of itemsDGT-OmegaT is Searching... and Searching... |
|
|
|
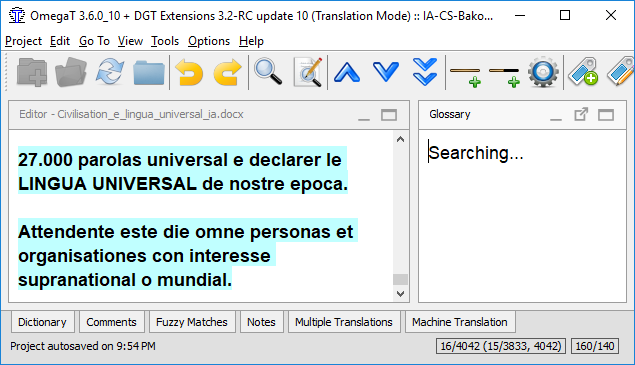
Glossary: 91 000 of items
Document: 4042 segments Searching... and Searching... |
|
|
|
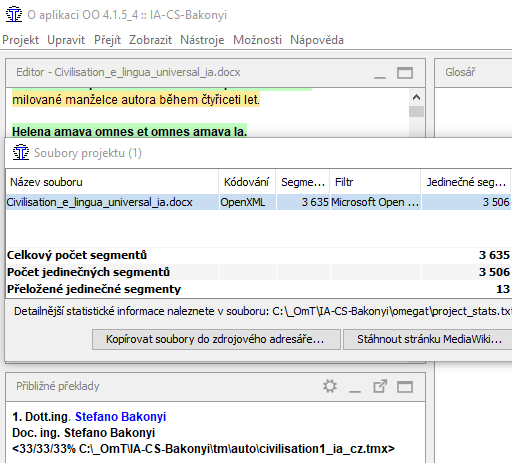
in OmegaT has same document3635 segments> |
|
|
|
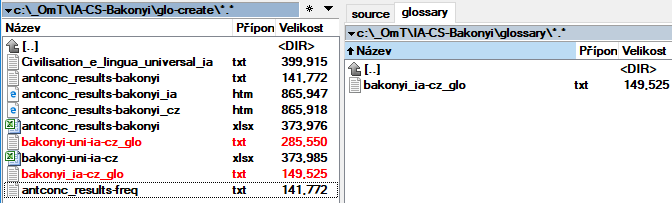
I shall create a smaller glossary only from words they are in source document, I name it bakonyi_ia_cs_glo.txt in source are only one word expression |
|
|
|
Now are glossary items visible
Tokenisation: universal |

| |
| and works very slowly: 12 segments per 69 seconds |
|
|
|
Instead of words from glossary
there is a mishmash |

|
|
| Set-up | Should I change some possibility? |
|
|
|
|